はじめに
ひょんなことからデータサイエンスを学ぶことになった私ILab_01が探索的データ分析 (EDA) に挑戦するという記事です。
プログラミング言語はPythonを使用しています。
以下、Jupyter Notebook風にコードと実行結果を書きながら、私が頭で考えていたことをつらつらと書いていきます。
実行結果と考察
# ひとまずデータを読み込む
import seaborn as sns
print(sns.get_dataset_names())
df = sns.load_dataset('iris')
df[‘anagrams’, ‘anscombe’, ‘attention’, ‘brain_networks’, ‘car_crashes’, ‘diamonds’, ‘dots’, ‘dowjones’, ‘exercise’, ‘flights’, ‘fmri’, ‘geyser’, ‘glue’, ‘healthexp’, ‘iris’, ‘mpg’, ‘penguins’, ‘planets’, ‘seaice’, ‘taxis’, ‘tips’, ‘titanic’]
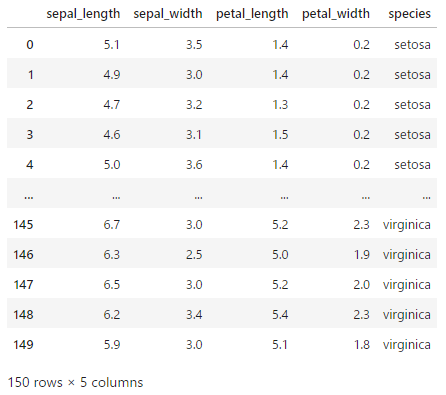
- sepal_length : ガクの長さ
- sepal_width : ガクの幅
- petal_length : 花弁の長さ
- petal_width : 花弁の幅
- species : アヤメの種類
アヤメの種類をうまい具合に分類したいというデータセットらしい。
# アヤメの種類を見てみる
df['species'].unique()array([‘setosa’, ‘versicolor’, ‘virginica’], dtype=object)
#各種の個数は?
df['species'].value_counts()species
setosa 50
versicolor 50
virginica 50
Name: count, dtype: int64# 欠損値はある? → 全て150件なので無さそう
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length 150 non-null float64
1 sepal_width 150 non-null float64
2 petal_length 150 non-null float64
3 petal_width 150 non-null float64
4 species 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB# ひとまず、散布図行列を見てみる。
sns.pairplot(df, hue='species')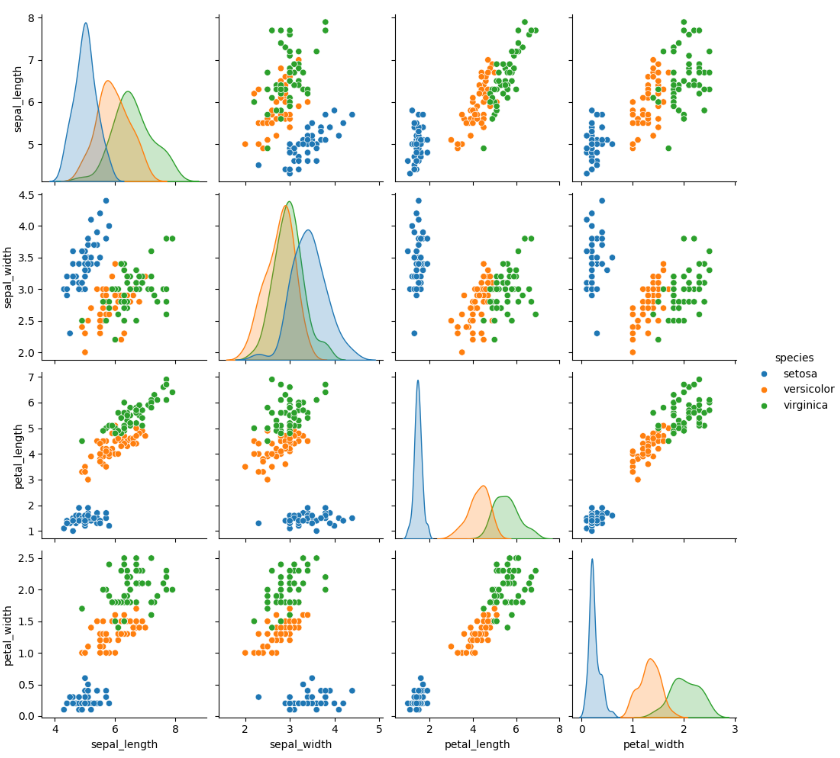
- petal_lengthのヒストグラムを見ると、割ときれいに種が別れているので、分類に使えるかもしれない。
- 同じくpetal_widthも比較的きれいに種を分けるらしい
# まずはデータセットを説明変数Xと目的変数yに分ける
X = df.drop(columns=['species'])
print(X.head())
y = df['species']
print(y.head())
# 学習用とテスト用にデータを分ける
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) sepal_length sepal_width petal_length petal_width
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
0 setosa
1 setosa
2 setosa
3 setosa
4 setosa
Name: species, dtype: object# 決定木モデルを作る
from sklearn import tree
model = tree.DecisionTreeClassifier(max_depth=2, random_state=0)
# 学習
model.fit(X_train, y_train)
# 推論
y_pred = model.predict(X_test)
# 精度の評価
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred)) precision recall f1-score support
setosa 1.00 1.00 1.00 16
versicolor 0.85 0.94 0.89 18
virginica 0.89 0.73 0.80 11
accuracy 0.91 45
macro avg 0.91 0.89 0.90 45
weighted avg 0.91 0.91 0.91 45※supportは各ラベル(種)の出力数
f1-scoreでみると、どれも0.8以上で予測している。
macro aveはラベルの単純な平均。weighted aveは件数を考慮して重み付けされた平均。
# 決定木を可視化する
from sklearn.tree import plot_tree
plot_tree(model, feature_names=X_train.columns, filled=True) # filledは四角の色付け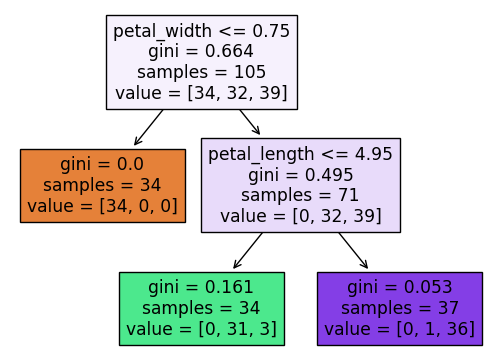
自分なりの結論
やはり、petal_widthとpetal_lengthである程度、種を分類できるようだ。
データサイエンスに関する記事はメニューバーの「データサイエンス」からどうぞ
コメント